Since price (and all data driven indicators) is a deterministic function of orders and the matching algorithm, it's reasonable to model random "traders" (i.e. or random orders) instead of random price. Here are a couple of directions that I consider:
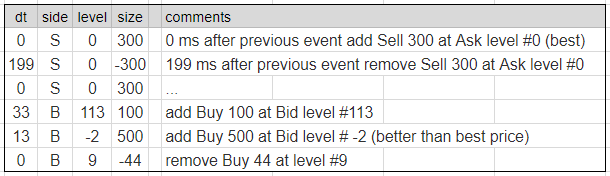
1. Based on historical order-by-order full depth data. Suppose, I convert millions of data events into a form like this:
- dT - time diff from the previous event
- ActionType - Send or Cancel or Modify an order
- Side - Buy or Sell
- PriceLevel - relative distance to the best Bid/Ask according the side Buy or Sell (aggressive orders can be represented by "negative distance")
- Quantity - size of the order
2. Similar to the above, but each of these fields will have a separate probability distribution. These distributions can still be derived from empirical/historical data, but the resulting action in most cases will not be a replication of any of actions in the original data.
What model do you think is better? Both seem simple to implement, but the first model requires to solve the cases of cancel or modify actions when order of such size doesn't exist at specified price level. Alternatively, I can implement both, and let them compete with each other. Are there additional models of random orders / traders?