
In some mechanical engineering applications, a spline's undershoot/overshoot can be the optimal solution because it minimizes stress, energy, or vibration.
ME is kind of different because you might redundancy; CAD/CAM drawings introduce tolerance dimensioning to allow for expansion, oveheating etc. So, maybe yes but my memory is slipping. Renault used Bezier and NURBS.
But not for bootstrapping the 30-year curve building; splines shoot below zero!. Hagan and West discuss this.
This really does depend on the domain.
Yes. aka what are the requirements?
Serving the Quantitative Finance Community
-

- Traden4Alpha
- Posts: 3300
- Joined:
Re: Universal Approximation theorem
The use of splines (and desirability of overshoot/undershoot) can happen in the design of bent forms, springs, and cams. Even aside from dimensional tolerance issues, the wiggle in the shape may be optimal. And then there's subjective taste and whether splines are simply pretty.In some mechanical engineering applications, a spline's undershoot/overshoot can be the optimal solution because it minimizes stress, energy, or vibration.
ME is kind of different because you might redundancy; CAD/CAM drawings introduce tolerance dimensioning to allow for expansion, oveheating etc. So, maybe yes but my memory is slipping. Renault used Bezier and NURBS.
But not for bootstrapping the 30-year curve building; splines shoot below zero!. Hagan and West discuss this.
This really does depend on the domain.
Yes. aka what are the requirements?
Clearly some curve building applications operate under different constraints that splines fail to respect and (mis)using splines carries a cost of some modeled magnitude.
If one is talking of "universal approximation," then maybe we're forced to acknowledge that diametrically opposite requirements of different applications (e.g., must overshoot vs. cannot overshoot) may rule out entire classes of curve fitting that don't have an easy switch or parameter for control their behavior.
There's also the software issue of a library's inability to control who calls it. Maybe it's in the contract with some curve fitting modules saying "danger: may undershoot or overshoot" and others saying "danger: does not undershoot or overshoot".
-

- Cuchulainn
- Posts: 22924
- Joined:
Re: Universal Approximation theorem
At the end of the day, splines are just vulgus fractionum investigando exposuimus,
Thinking about it
A. Input can be 1) discrete 2) continuous (up to a degree)
A.1 can be nice and uniformly or very sparse/clumped. Gradient unknown.
B. we have some properties we would like the output to have
1) reflects the input 2) nice and smooth.
We now need to decides on a transformed (A->B). Which one depends on the combination of A and B. This is where maths says it's possible or not.
You can interpolate a straight line with a cubic spline and it is beautiful.
Extreme: interpolate GBM, it is nowhere differentiable. And nice functions like boundary layer [$]exp(-x^2/\varepsilon)[$], [$]\varepsilon[$] small.
Thinking about it
A. Input can be 1) discrete 2) continuous (up to a degree)
A.1 can be nice and uniformly or very sparse/clumped. Gradient unknown.
B. we have some properties we would like the output to have
1) reflects the input 2) nice and smooth.
We now need to decides on a transformed (A->B). Which one depends on the combination of A and B. This is where maths says it's possible or not.
You can interpolate a straight line with a cubic spline and it is beautiful.
Extreme: interpolate GBM, it is nowhere differentiable. And nice functions like boundary layer [$]exp(-x^2/\varepsilon)[$], [$]\varepsilon[$] small.
Last edited by Cuchulainn on July 10th, 2017, 7:52 pm, edited 4 times in total.
-
- Traden4Alpha
- Posts: 3300
- Joined:
Re: Universal Approximation theorem
LOL! That language is older than Pink Floyd, what? Yet I fear the only Latin I know came from watching Monty Python so your phrase is unintelligible to me. Or is it a Harry Potter incantation? I can't tell!At the end of the day, splines are just vulgus fractionum investigando exposuimus,
Splines are the Husqvarna of modeling -- dangerous & powerful.
-
- Cuchulainn
- Posts: 22924
- Joined:
Re: Universal Approximation theorem
I agree.The use of splines (and desirability of overshoot/undershoot) can happen in the design of bent forms, springs, and cams. Even aside from dimensional tolerance issues, the wiggle in the shape may be optimal. And then there's subjective taste and whether splines are simply pretty.In some mechanical engineering applications, a spline's undershoot/overshoot can be the optimal solution because it minimizes stress, energy, or vibration.
ME is kind of different because you might redundancy; CAD/CAM drawings introduce tolerance dimensioning to allow for expansion, oveheating etc. So, maybe yes but my memory is slipping. Renault used Bezier and NURBS.
But not for bootstrapping the 30-year curve building; splines shoot below zero!. Hagan and West discuss this.
This really does depend on the domain.
Yes. aka what are the requirements?
Clearly some curve building applications operate under different constraints that splines fail to respect and (mis)using splines carries a cost of some modeled magnitude.
If one is talking of "universal approximation," then maybe we're forced to acknowledge that diametrically opposite requirements of different applications (e.g., must overshoot vs. cannot overshoot) may rule out entire classes of curve fitting that don't have an easy switch or parameter for control their behavior.
There's also the software issue of a library's inability to control who calls it. Maybe it's in the contract with some curve fitting modules saying "danger: may undershoot or overshoot" and others saying "danger: does not undershoot or overshoot".
-
- Cuchulainn
- Posts: 22924
- Joined:
Re: Universal Approximation theorem
It's Latin for "vulgar polynomial"LOL! That language is older than Pink Floyd, what? Yet I fear the only Latin I know came from watching Monty Python so your phrase is unintelligible to me. Or is it a Harry Potter incantation? I can't tell!At the end of the day, splines are just vulgus fractionum investigando exposuimus,
Splines are the Husqvarna of modeling -- dangerous & powerful.
Euler loved his fractionum investigando exposuimus, so he did.
-
- Traden4Alpha
- Posts: 3300
- Joined:
Re: Universal Approximation theorem
So the Latin curve fit for "vulgar polynomial" overshoots on character count.It's Latin for "vulgar polynomial"LOL! That language is older than Pink Floyd, what? Yet I fear the only Latin I know came from watching Monty Python so your phrase is unintelligible to me. Or is it a Harry Potter incantation? I can't tell!At the end of the day, splines are just vulgus fractionum investigando exposuimus,
Splines are the Husqvarna of modeling -- dangerous & powerful.Long-winded.
Euler loved his fractionum investigando exposuimus, so he did.
(But I still think it makes a good Harry Potter spell!)

Re: Universal Approximation theorem
Splines and polynomial can be made to fit the data exactly, so from that perspective you can't asses which one is better. Fitting Heston or neural networks will not give perfect fits, you'll have some cost function you want to minimize.
Like t4a said, you look at out sample performance. This is because in this case the objective is "interpolation", you want to use the model to predict the y values for new x values. That objective directly leads to techniques like crossvalidation for evaluating and comparing performance.
Smoothness will be rewarded via crossvalidation if the data shows smoothness.
Monoticity, positivity etc (a priori facts about the problem statement) are imposed by variable transforms (not via cost function terms) Eg when modeling default probabilities people use logit models which enforce model outputs to always be between 0 and 1. When classifying -is this a picture of a dog, horse or car?- then it's common to use the softmax transform that ensures that all values are between 0 and 1 but also sum up to 1.
Like t4a said, you look at out sample performance. This is because in this case the objective is "interpolation", you want to use the model to predict the y values for new x values. That objective directly leads to techniques like crossvalidation for evaluating and comparing performance.
Smoothness will be rewarded via crossvalidation if the data shows smoothness.
Monoticity, positivity etc (a priori facts about the problem statement) are imposed by variable transforms (not via cost function terms) Eg when modeling default probabilities people use logit models which enforce model outputs to always be between 0 and 1. When classifying -is this a picture of a dog, horse or car?- then it's common to use the softmax transform that ensures that all values are between 0 and 1 but also sum up to 1.
-
- Cuchulainn
- Posts: 22924
- Joined:
Re: Universal Approximation theorem
Let's say you have an image full of 2d shapes (e.g. a CAD drawing of a house) and I want to find all the rectangles (e.g. doors and windows). How can I do that? Will cubic splines work?
The kind of answer I would expect is the steps to do this to give insight of how NN folk look at life.
The kind of answer I would expect is the steps to do this to give insight of how NN folk look at life.
Re: Universal Approximation theorem
This is called image segmentation, it's also used eg to detect faces in photo software.
You start out with making a training set. This would be a set of images where the rectangles are labeled.
I've seen two approaches depending on what you want. One option is that you provide a Boolean mask of the same size as your image where each pixel is true or false as being part of a rectangle. This makes it a classification task, the model will output for each pixel whether it's part of a rectangle or not, and you'll use cross entropy as loss function as a measure of how good it it. Here is an example of what you would give as an example during training. Btw this is called "supervised learning" because you give clear examples of exactly what you want the network to do. In this example below they are trying to teach it to detect bicycles and riders.

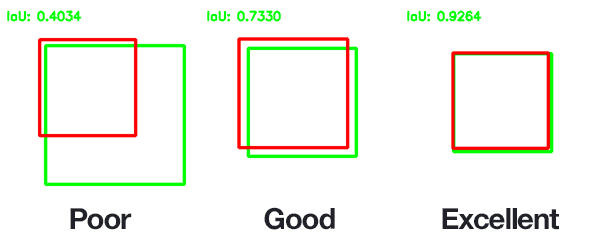
A second method is to provide corner coordinates of a box in which your doors/windows are. The target output of the network is 4 floats, and this makes is a regression task. A common loss function is to minimize the mismatch between the rectangle the model suggests and the true rectangle. This is called "intersect over union"

Once you have a training set of examples you then typically use a deep "convolutional" neural network to learn the relationship between the input and target output. The network build their own filters during training, things like edge detectors. This is a good example of the benefits of deep neural networks. In the old days "domain experts" would build their own filters for feature extraction, which was laberous and suboptimal. Interestingly these filters tge neural network creates typically end up being things that are well known, eg they always end up creating Gabor filters in the first layers, and more complicated concept in higher layers

You start out with making a training set. This would be a set of images where the rectangles are labeled.
I've seen two approaches depending on what you want. One option is that you provide a Boolean mask of the same size as your image where each pixel is true or false as being part of a rectangle. This makes it a classification task, the model will output for each pixel whether it's part of a rectangle or not, and you'll use cross entropy as loss function as a measure of how good it it. Here is an example of what you would give as an example during training. Btw this is called "supervised learning" because you give clear examples of exactly what you want the network to do. In this example below they are trying to teach it to detect bicycles and riders.
A second method is to provide corner coordinates of a box in which your doors/windows are. The target output of the network is 4 floats, and this makes is a regression task. A common loss function is to minimize the mismatch between the rectangle the model suggests and the true rectangle. This is called "intersect over union"
Once you have a training set of examples you then typically use a deep "convolutional" neural network to learn the relationship between the input and target output. The network build their own filters during training, things like edge detectors. This is a good example of the benefits of deep neural networks. In the old days "domain experts" would build their own filters for feature extraction, which was laberous and suboptimal. Interestingly these filters tge neural network creates typically end up being things that are well known, eg they always end up creating Gabor filters in the first layers, and more complicated concept in higher layers
-
- Traden4Alpha
- Posts: 3300
- Joined:
Re: Universal Approximation theorem
Indeed, it is a great example.
I have seen image matching systems that did use splines. It was a project at a former employer that was for tracking sea ice in the Arctic for JPL/NASA. The challenge was to recognize and track the icebergs and floating plates of ice across months and years as they wandered around the ocean & icepack. The advantage of representing the outline of each major ice floe as a spline was that was that splines more robust to changes in ice object shape. Unlike many curve-fitting methods in which each coefficient of the curve fit is a function of ALL of the data, spline coefficients are only affected by a local neighborhood. If an ice feature lost a chunk, the spline coefficients in the remaining part did not change and could still be matched. This was back in the mid 80s, ran on a Vax 11/750, and was definitely an example of heavy thought by human engineers rather than throwing terabytes of data onto some automagical adaptive learning system on a GPU array.
I have seen image matching systems that did use splines. It was a project at a former employer that was for tracking sea ice in the Arctic for JPL/NASA. The challenge was to recognize and track the icebergs and floating plates of ice across months and years as they wandered around the ocean & icepack. The advantage of representing the outline of each major ice floe as a spline was that was that splines more robust to changes in ice object shape. Unlike many curve-fitting methods in which each coefficient of the curve fit is a function of ALL of the data, spline coefficients are only affected by a local neighborhood. If an ice feature lost a chunk, the spline coefficients in the remaining part did not change and could still be matched. This was back in the mid 80s, ran on a Vax 11/750, and was definitely an example of heavy thought by human engineers rather than throwing terabytes of data onto some automagical adaptive learning system on a GPU array.
-
- Cuchulainn
- Posts: 22924
- Joined:
Re: Universal Approximation theorem
dbl
Last edited by Cuchulainn on July 15th, 2017, 8:14 pm, edited 1 time in total.
-
- Cuchulainn
- Posts: 22924
- Joined:
Re: Universal Approximation theorem
dbl
Last edited by Cuchulainn on July 15th, 2017, 8:13 pm, edited 1 time in total.
-
- Cuchulainn
- Posts: 22924
- Joined:
Re: Universal Approximation theorem
Nice! These are called piecewise polynomial with compact support in FEM jargon. Linear 'hat' functions are the simplest kind (zero outside [x-h, x+h], where h is the mesh size) and only have coupling to two neighbouring hat functions. If a part of Antarctica the size of Galway breaks off then local changes have local impact.
https://en.wikiversity.org/wiki/Introdu ... _functions
My hunch is with ANN you have to retrain for all of Antarctica? Yuge. Can you teach NN to speaka the cubic splines without rummaging through bitmaps?
Follow-on Q: why and when to train? i.e. under which circumstances.
// Vax 11/750/780 and Vax/VMS best OS ever.
https://en.wikiversity.org/wiki/Introdu ... _functions
My hunch is with ANN you have to retrain for all of Antarctica? Yuge. Can you teach NN to speaka the cubic splines without rummaging through bitmaps?
Follow-on Q: why and when to train? i.e. under which circumstances.
// Vax 11/750/780 and Vax/VMS best OS ever.