
Serving the Quantitative Finance Community
-

- katastrofa
- Posts: 7929
- Joined:
- Location: Event Horizon
Re: If you are bored with Deep Networks
Another crazy question. I'm wondering about the opposite to what you wrote about the proximity of the classification boundary: your input does not cover the full space - the points are probably denser in some regions than others and there are empty areas in this space. Based on my understanding of Voronoi partition (as I know it from research in crystallography), these empty areas will also be assigned to some clusters - practically at random. What if the problem is like in situation 1 from the attached picture (you use the classifier trained on black points to assign the red x)?
Last edited by katastrofa on June 11th, 2018, 10:40 pm, edited 1 time in total.
-
- katastrofa
- Posts: 7929
- Joined:
- Location: Event Horizon
Re: If you are bored with Deep Networks
@Cuchulainn: "This probably means that the problem is "ill-posed" in some way."
Sometimes it's easier to use a scotch tape rather than shift a paradigm
Sometimes it's easier to use a scotch tape rather than shift a paradigm
Last edited by katastrofa on June 11th, 2018, 10:18 pm, edited 1 time in total.
-

- Traden4Alpha
- Posts: 3300
- Joined:
Re: If you are bored with Deep Networks
The Voronoi partition would create the classification boundary assuming the populations really are separable. And, yes, it can be a bit random-seeming because the directions of the separating lines (or hyperplanes) that radiate off into empty space are defined entirely by only two data points which makes them extremely sensitive to the locations of those data points.Another crazy question. I'm wondering about the opposite to what you wrote about the proximity of the classification boundary: your input does not cover the full space - the points are probably denser in some regions than others and there are empty areas in this space. Based on my understanding of Voronoi partition, these empty areas will also be assigned to some clusters - practically at random. What if the problem is like in situation 1 from the attached picture?
The more likely condition is an overlap in the populations such that a given region of the space has a non-zero probability of being associated with two or more types. That is, there may be some images of dogs that are indistinguishable from some images of cats.
If the training data points do not cover the full space, there's the fundamental problem that the empty parts really cannot be classified without making extrapolating assumptions about the distributions of the categories (i.e., how do the tails of the distributions extend into the empty space). Moreover, the empty space may correspond to objects not in the set of classified categories (e.g., velociraptors) or non-sense images (left-half cat, right-half dog images).
-

- Cuchulainn
- Posts: 22924
- Joined:
Re: If you are bored with Deep Networks
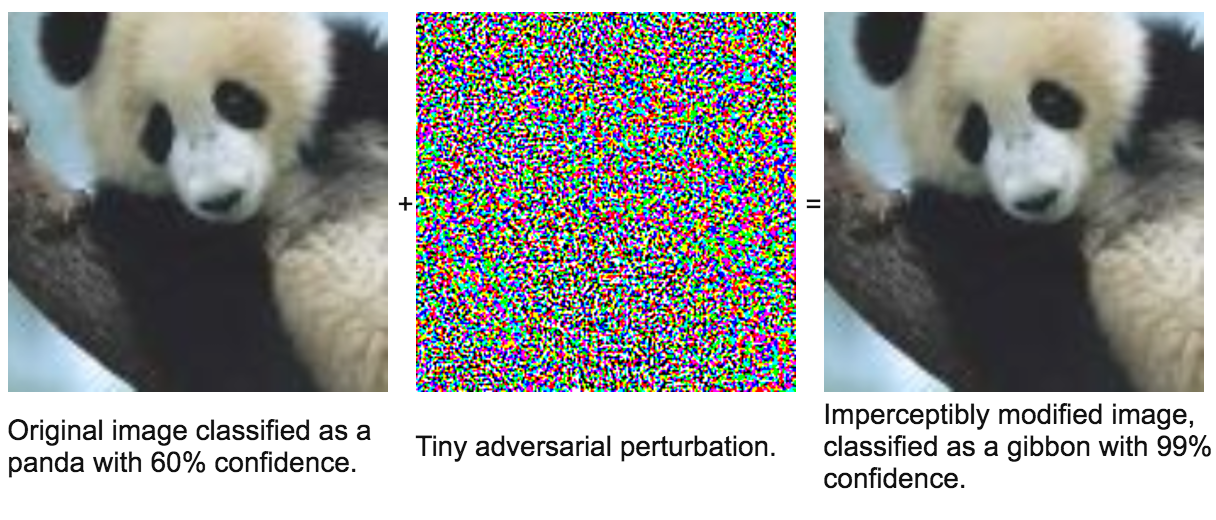
Let's take Goodfellow's adversarial example again, page 261@Cuchilainn: "This probably means that the problem is "ill-posed" in some way."
Sometimes it's easier to use a scotch tape rather than shift a paradigm
Problem space: it is a panda even when the image is perturbed by a small amount. That's a fact. And this is reality to be modelled.
Representation space (algorithm). The algo recognises a panda in the unperturbed case and in the perturbed case it is a funky gibbon. Your algo must also return a panda in both cases.
Conclusion: the algorithm is wrong. I can't think of any other explanation.
//
The analogy in another domain in inventing negative probabilities and other profanities (name-dropping names like Dirac and Feynman to help the cause) to explain away when the binomial breaks down. It's quite possibly fallacious thinking. I suspect that this is becoming the standard 'scientific method', i.e fixing and fudging.
Last edited by Cuchulainn on June 11th, 2018, 8:18 pm, edited 4 times in total.
-
- Traden4Alpha
- Posts: 3300
- Joined:
Re: If you are bored with Deep Networks
Is the "perturbation" a physically accurate one? And was the net trained with examples perturbed in this way?Let's take Goodfellow's adversarial example page 261@Cuchilainn: "This probably means that the problem is "ill-posed" in some way."
Sometimes it's easier to use a scotch tape rather than shift a paradigm
Problem space: it is a panda even when the image is perturbed by a small amount. That's a fact. .
Representation space (algorithm). The algo recognises a panda in the unperturbed and in the perturbed case it a funky gibbon. Your algo must also return a panda in both cases.
Conclusion: the algorithm is wrong. I can't think of any other explanation.
//
The analogy in another domain in inventing negative probabilities and other profanities (name-dropping names like Dirac and Feynman) to explain away when the binomial breaks down. It's quite possibly fallacious thinking. I suspect that this is becoming the standard 'scientific method', i.e fixing and fudging.
-
- Cuchulainn
- Posts: 22924
- Joined:
Re: If you are bored with Deep Networks
Is the "perturbation" a physically accurate one?
Humans see it as a panda. So yes. It looks awfully like a panda.
And was the net trained with examples perturbed in this way?
I don't do pandas. So I don't know. ISM??
Humans see it as a panda. So yes. It looks awfully like a panda.
And was the net trained with examples perturbed in this way?
I don't do pandas. So I don't know. ISM??
-
- Cuchulainn
- Posts: 22924
- Joined:
Re: If you are bored with Deep Networks
Some linksAnother crazy question. I'm wondering about the opposite to what you wrote about the proximity of the classification boundary: your input does not cover the full space - the points are probably denser in some regions than others and there are empty areas in this space. Based on my understanding of Voronoi partition, these empty areas will also be assigned to some clusters - practically at random. What if the problem is like in situation 1 from the attached picture?
https://www.maths.tcd.ie/~odunlain/papers.html
-
- katastrofa
- Posts: 7929
- Joined:
- Location: Event Horizon
Re: If you are bored with Deep Networks
It would be a problem if a scientist did that (use Scotch tape). It's fine though when it's an engineer. One rolls up the sleeves and get hands dirty in the guts of the algorithm. There are probably several effects that make it fail - they need to be identified and fixed. That can be the way to developing a more robust approach. Just my basic philosophy - you probably know better how it works in both cases.Let's take Goodfellow's adversarial example again, page 261@Cuchilainn: "This probably means that the problem is "ill-posed" in some way."
Sometimes it's easier to use a scotch tape rather than shift a paradigm
Problem space: it is a panda even when the image is perturbed by a small amount. That's a fact. And this is reality to be modelled.
Representation space (algorithm). The algo recognises a panda in the unperturbed case and in the perturbed case it is a funky gibbon. Your algo must also return a panda in both cases.
Conclusion: the algorithm is wrong. I can't think of any other explanation.
//
The analogy in another domain in inventing negative probabilities and other profanities (name-dropping names like Dirac and Feynman to help the cause) to explain away when the binomial breaks down. It's quite possibly fallacious thinking. I suspect that this is becoming the standard 'scientific method', i.e fixing and fudging.
-
- Cuchulainn
- Posts: 22924
- Joined:
Re: If you are bored with Deep Networks
That is probably not a totally 100% accurate interpretation. Analogies are not always helpful.
Goodfellow et al is a book from 2016.
Besides, should we not be talking about finance cases rather than gibbon derriere?
Goodfellow et al is a book from 2016.
Besides, should we not be talking about finance cases rather than gibbon derriere?
-
- katastrofa
- Posts: 7929
- Joined:
- Location: Event Horizon
Re: If you are bored with Deep Networks
Maybe you just have too little data to train the classifier properly. If you want to achieve a precision higher than a human eye (vide panda + returbed panda), I'm wondering if enough data exists.I think if this was the whole story, then we wouldn't observe adversarial examples arising from the training set, because then all points would have been comfortably away from the classification boundary. But we do observe them also in the training sets.Another crazy question. I'm wondering about the opposite to what you wrote about the proximity of the classification boundary: your input does not cover the full space - the points are probably denser in some regions than others and there are empty areas in this space. Based on my understanding of Voronoi partition (as I know it from research in crystallography), these empty areas will also be assigned to some clusters - practically at random. What if the problem is like in situation 1 from the attached picture (you use the classifier trained on black points to assign the red x)?
-
- katastrofa
- Posts: 7929
- Joined:
- Location: Event Horizon
Re: If you are bored with Deep Networks
Do we? Like stupid cows eating wild cherry leaves or, similarly, your very own wife deciding to have some rest in the shadow of Manchineel
-
- Traden4Alpha
- Posts: 3300
- Joined:
Re: If you are bored with Deep Networks
Humans and animals get a staggering amount of data just by wandering around their environment and interacting with things.I wonder about that too! But somehow, humans and other animals cope with that.
The "frames" of the eye's video stream may not be truly independent samples but they are something much more powerful on two levels. First, the motion of the observer or the subject object enhances the ability to segment the focal object from the background. Second, the stream of frames traces a meandering but continuous curve in the classifier space. That would seem to be more powerful data than disconnected points in space with no clues as to whether adjacent points in the space are the same object from a slightly different angle (with the empty space between frame-points being a member of the same subject class) or totally different sample (with the empty space between independent points potentially being a member of other classes).
And within the limits of foveal vision, the humans and animals actually get parallel classification data from the multiple objects in the environment as well as learning cues for correlations in object occurrences (e.g., having recognized a hamburger, the pale rod-like objects next to the hamburger are probably french fries, not sticks).
Even at only 10 frames per second, only 6 salient objects in the visual field, and 12 hours of awareness per day, a young creature gathers a billion object-impression-samples per year, which is 10X the ImageNet database.
-
- Traden4Alpha
- Posts: 3300
- Joined:
Re: If you are bored with Deep Networks
I'm not saying animals have superior vision per se only that they have access to superior training data.
There is much we don't know about how humans and animals learn to see. But it is clear that they fail to learn to see if only exposed to disembodied snapshots the way current AI systems are. Even streaming imagery is insufficient. Interacting with the world, moving through it, reaching out and touching things seems totally essential.
It would seem that infants at 12 months already have a sense of "objects" in that they anticipate that a object passing behind another object will appear on the other side. I would surmise that "object" recognition arises from interacting with the world and discovering that some things can move independently of others or noticing patches of visual input moving independently of other patches of visual input. Probably the first patches of visual input that resolve into objects would be the baby's own hands and feet as they move toward the face and mouth.
The data collected by young animals may not be labelled in the linguistic or set theoretic sense but they are clustered by continuity over time, similarity across instances, and distinctness from other elements of sensory inputs. I would suspect that many children confuse cats and dogs when young but then learn quickly that the two categories of creatures have distinct visual and behavioral signatures. Later they learn the labels.
There is much we don't know about how humans and animals learn to see. But it is clear that they fail to learn to see if only exposed to disembodied snapshots the way current AI systems are. Even streaming imagery is insufficient. Interacting with the world, moving through it, reaching out and touching things seems totally essential.
It would seem that infants at 12 months already have a sense of "objects" in that they anticipate that a object passing behind another object will appear on the other side. I would surmise that "object" recognition arises from interacting with the world and discovering that some things can move independently of others or noticing patches of visual input moving independently of other patches of visual input. Probably the first patches of visual input that resolve into objects would be the baby's own hands and feet as they move toward the face and mouth.
The data collected by young animals may not be labelled in the linguistic or set theoretic sense but they are clustered by continuity over time, similarity across instances, and distinctness from other elements of sensory inputs. I would suspect that many children confuse cats and dogs when young but then learn quickly that the two categories of creatures have distinct visual and behavioral signatures. Later they learn the labels.
-
- Cuchulainn
- Posts: 22924
- Joined:
Re: If you are bored with Deep Networks
Nice.On the other hand:In general, there is so much we simply don't know about how biological brains work that building algorithms based on what we guess about how they work can be a road to nowhere. It's clear we need more than CNNs, not clear what exactly it is, and also not at all clear that we should replicate closely the messy result of evolution of natural selection. E.g. biological brains have a lot of redundancy in them because they have to be resistant to damage (getting whacked on the head). Artificial neural networks don't have to be.
- most of this data is not labelled
- we don't actually know how much of this data is remembered and available for more than one pass of the "learning algorithm"
- we don't know how detailed a representation is remembered
- we know that a lot of what we think we "see" is actually our brain filling in the gaps in what the eyes send to it (this is where many optical illusions come from)
- neural networks also rely on contextual information to classify objects, e.g. the presence of waves in the photo makes it more likely that a CNN will think it saw a whale in it
You also seem to engage in a circular argument in the last two paragraphs of your post, by attempting to explain the superior vision abilities of animals by referring to data which are available to them thanks to the same vision or other cognitive abilities ("get data from objects" - how do they know they see objects? how do they combine points of light into objects? how do they represent an object in their memory for further processing?). If we train our CNNs to segment bitmaps into objects and remember them, half of our work will be done
It's a very tricky subject. It's easy to fall into these traps. You should carefully define terms you're using.
-
- Traden4Alpha
- Posts: 3300
- Joined:
Re: If you are bored with Deep Networks
Creature only passs the mirror test after extensive training about life. Human babies, for example, can't pass the mirror test until somewhere between 13 and 24 months.That's not true: at least primates can recognise photographs. Many animals also pass the infamous "mirror test".There is much we don't know about how humans and animals learn to see. But it is clear that they fail to learn to see if only exposed to disembodied snapshots the way current AI systems are. Even streaming imagery is insufficient. Interacting with the world, moving through it, reaching out and touching things seems totally essential.